VGGNet
- Paper Implementation : "Very deep convolutional networks for large-scale image recognition.(2014)"
- Code Practice : 아래 Colab과 Git 링크를 통해 어떻게 구현 되었는지 구체적으로 확인해 보실 수 있습니다.

Description
- VGG Network:
- VGG Networks는 총 6개로 구성되어 있으며 VGG11(A)과 VGG16(D)을 구현해 보았습니다.
A = VGG-11, A-LRN = VGG-11(LRN), B = VGG-13,C = VGG-16(Conv1), D = VGG-16, E = VGG-19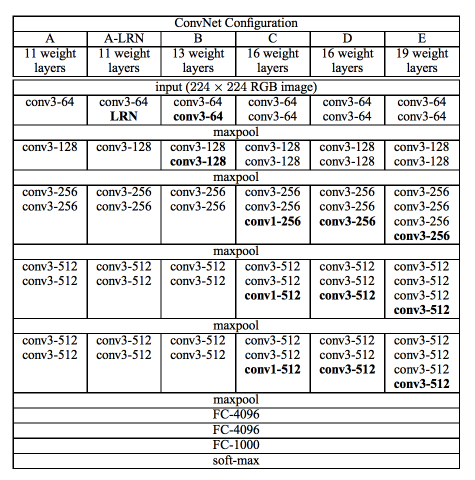
Figure 1. VGGNet Architecture : Simonyan, K. & Zisserman, A. (2014)
2. Convolution Filter:
- Receptive field란? Convolution filter가 한번에 보는 영역의 크기를 의미합니다. 논문과 마찬가지로 3x3을 적용했습니다. 또한, 학습이 진행되면서 Spatial information을 보존 할 수 있게 1x1 convolution filter가 활용되었습니다.
3. Convolution Stride:
- Convolution Stride는 1로 고정 하였습니다.
4. Max-Pooling Layer :
- Max-Pooling층의 Kernel size, stride, layer는 다음과 같이 구성하였습니다.
- kernel size = 2x2
- stride = 2
- number of Max-Pooling layer = 5
5. Fully Connected Layer(FC Layer):
- 논문에서 제시된 FC층은 다음과 같습니다.
- 2개의 4096 channel
- 1개의 1000 channel
- 1개의 Softmax
6. Local Response Normalization(LRN):
- LRN layer가 메모리 점유율과 계산 복잡도를 증대 시켜 사용하지 않았습니다.
7. Initialization(Weight and Bias):
- Weight 과 Bias는 다음과 같이 초기화 하였습니다.
- mean = 0 , STD = 0.01, bias = 0
8. Image Preprocessing:
- 이미지 전처리는 shape, resize, center crop, mean subtraction을 적용하였습니다.
- Input image shape = 224x224x3
- resize = 256x256
- center crop = 224
- Mean subtraction of RGB per channel
9. Hyperparameter
- 논문에서 제시된 하이퍼파라미터와 실제 구현에 사용된 하이퍼파라미터는 다음과 같습니다.
- Optimizer = SGD -> Adam으로 변경
- Momentum = 0.9 -> 적용하지 않음
- Weight decay(L2) = 0.0005 -> 적용하지 않음
- Batch size = 256
- Learning rate = 0.1 -> 0.0001으로 변경
- Epoch = 20 to 100 -> 40 for VGG11A, 30 for VGG16D
- Dropout = 0.5
10. Test Results:
- Test 결과는 Accuracy, Loss, Classification Report, Confusion Matrix로 확인해 보실 수 있습니다.

11. Dataset:
- 논문에서 ImageNet 데이터셋을 사용했지만 제한적인 개발환경으로 인해 CIFAR-10을 사용했습니다.
- 논문 : ImageNet Large Scale Visual Recognition Challenge(ILSVRC)-2014
- 구현 : CIFAR-10
12. System Environment:
- Google Colab Pro Plus GPU : K80(Kepler), T4(Turing), and P100(Pascal)
- Jupyter Notebook, Visual Studio Code
Discussion
논문에서는 VGG11A를 대용량의 데이터로 사전학습 시킨 후 Weight과 Bias를 불러와 VGG16 모델에 적용하였습니다.그대로 구현해 본 결과, VGG11에서는 학습과 예측 모두 기대할 만한 결과를 나타냈습니다.
하지만 데이터셋의 차이 때문인지 VGG16에서 학습이 유의미하게 증가하지 않았고 예측도 불안정했습니다. 문제를 찾기 위해 weight 과 bias 초기화(initialization) 적용 유무를 비교해 보기로 했습니다.
VGG11의 경우 초기화를 적용유무와 상관 없이 안정적인 결과를 산출해 내었습니다. 하지만 , VGG16의 경우 초기화를 적용하지 않았을 때 정상적으로 학습 되었지만, 적용 할 경우 저조한 성능을 보여주었습니다. 정리하자면, 초기화의 유무에 따라 VGG16의 학습에 영향을 미칠 수 있음을 알게 되었고, 데이터셋의 크기, 사전학습의 양, 초기화 설정의 문제인지 추후 더 연구할 필요성을 알게 되었습니다.
Reference
[1] "[논문 구현] VGGNet 파이토치로 구현하기", For a better world,
2022년 9월 8일 수정, 2023년 1월 5일 접속, https://roytravel.tistory.com/337.
[2] "[논문리뷰] VGGNet(2014)리뷰와 파이토치 구현", 딥러닝 공부방,
2020년 12월 31일 수정, 2023년 1월 9일 접속, https://deep-learning-study.tistory.com/398.
[3] "1등보다 빛나는 2등, VGG-16", 루나, 2021년 7월 24일 수정, 2023년 1월 9일 접속, https://brunch.co.kr/@hvnpoet/126.
[4] "VGGnet(2014)", Seonghoon-Yu, 2021년 5월 16일 수정, 2023년 1월 9일 접속, https://github.com/Seonghoon-Yu/AI_Paper_Review/blob/master/Classification/VGGnet(2014).ipynb.
[5] "[논문리뷰] VGGnet(2014)설명", Inhovative AI, 2021년 9월 8일 수정,
2023년 1월 9일 접속, https://inhovation97.tistory.com/44.
[6] Simonyan, K. & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://arxiv.org/pdf/1409.1556.pdf
[7] Krizhevsky, A., & Hinton, G. (2009). Learning multiple layers of features from tiny images.http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf
[8] "The CIFAR-10 dataset", Alex Krizhevsky's home page, 2009년 작성, 2022년 12월 28일 접속, https://www.cs.toronto.edu/~kriz/cifar.html.
'Artificial Intelligence > 컴퓨터 비전 (CV)' 카테고리의 다른 글
| [PyTorch] Vision Transformer(ViT) 논문구현 (4) | 2023.02.16 |
|---|---|
| [PyTorch] ResNet 논문구현 (0) | 2023.02.12 |
| [PyTorch] GoogLeNet 논문구현 (0) | 2023.02.07 |
| [PyTorch] AlexNet 논문구현 (0) | 2023.02.06 |




댓글